
Alloy
The enforced pipeline architecture that scales cleanly, stays transparent, and enables customization where it matters.

Data Platforms Don’t Fail on Volume. They Fail on Chaos.
Most data platforms struggle to scale not because of data volume, but because of architectural inconsistency. As new pipelines are added, teams introduce new patterns, exceptions, and one-off designs that slowly fragment the platform.
Without a defined and enforced architecture, every new requirement becomes a design exercise. Over time, this leads to fragile workflows, operational complexity, and platforms that are expensive to change and difficult to trust.
Each pipeline becomes its own system
Operational complexity grows faster than data volume
Onboarding slows as tribal knowledge accumulates
Refactoring becomes risky and expensive
Alloy addresses this by enforcing a single, explicit pipeline architecture that every data pipeline follows.
What happens without enforced architecture
This is a real production data platform after years of custom pipeline development without a standardized architecture.
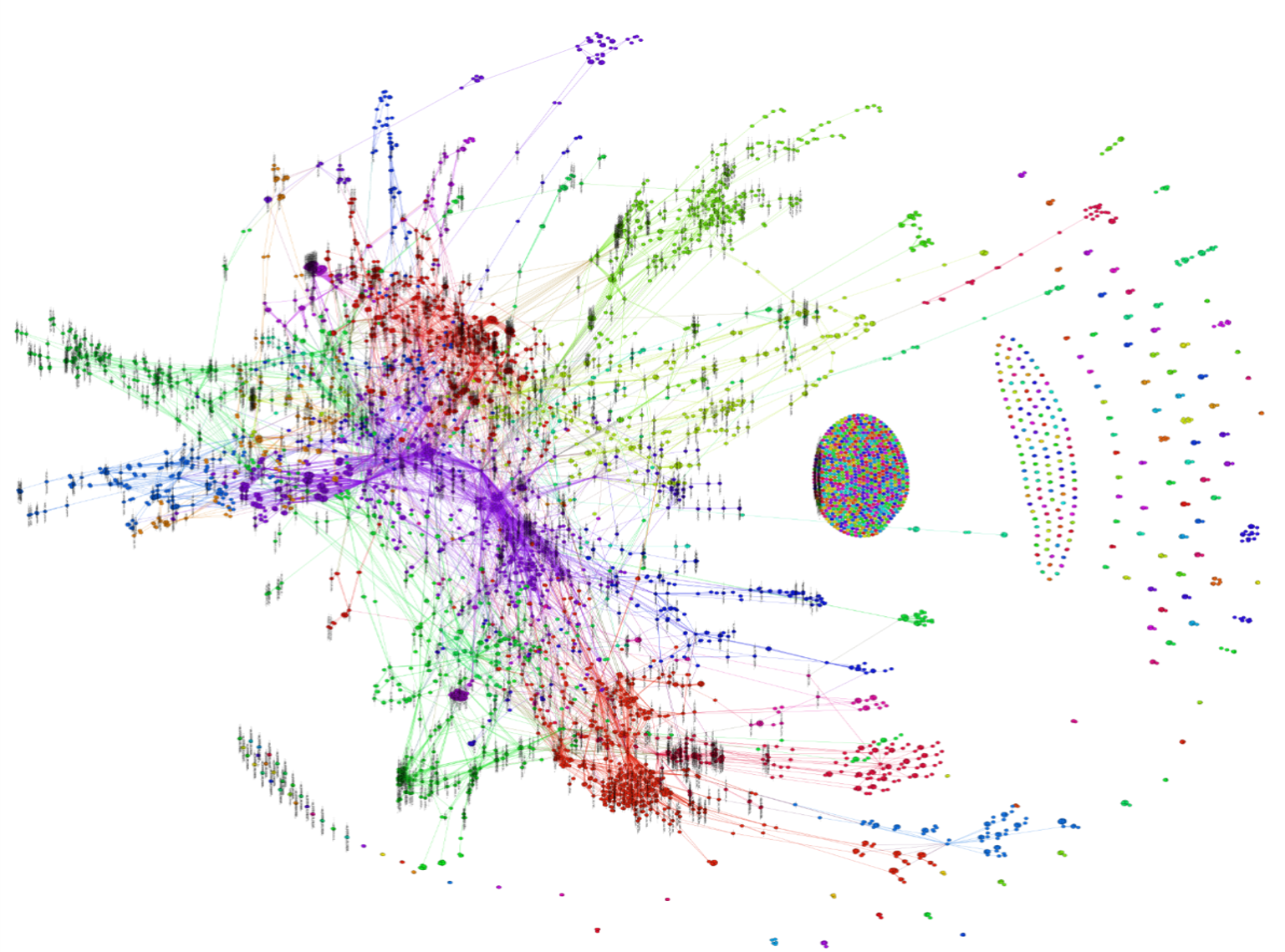
Each point represents a manually built code package.
Over time, systems like this become difficult to change, operate, or trust.
A Clear, Explicit Layered Architecture
Alloy enforces a single, named layer model that every data pipeline follows. Each layer has a clear purpose, and the boundaries between layers are explicit, so teams can understand and operate the platform without reverse-engineering hidden behavior.
There are no hidden layers, implicit stages, or shortcuts. Every pipeline moves through the same explicit architecture.
ORE
Raw source data enters the platform in its original form, providing a consistent and observable starting point.
MINERAL
Changes are detected and isolated so incremental processing is the default, not an optimization added later.
ALLOY
Data is enriched incrementally within a structured, repeatable transformation layer.
INGOT
Data is refined and consolidated into durable, reusable representations.
PRODUCT
Final outputs are delivered in a form optimized for analytics, applications, and downstream systems.
Standardized Execution, Built In
In Alloy, data pipelines do not rely on ad-hoc scripts or custom orchestration logic. The processes that move and transform data between layers are standardized and consistent across the platform, so teams build once and operate with confidence as the platform grows.
Predictable data movement
Data moves through the platform using consistent execution patterns, eliminating one-off workflows and hidden dependencies.
Incremental by default
Change detection and incremental processing are foundational behaviors, not optimizations added later as data volume grows.
Transparent operations
Because execution follows a known structure, teams can reason about pipeline behavior, troubleshoot issues, and make changes without reverse-engineering custom logic.
Designed to scale without redesign
As new pipelines are added, they inherit the same execution model, preventing complexity from compounding over time.
Declarative Logic, Embedded in the Platform
Ember is the declarative knowledge layer of DataForge. It defines how data should be shaped, validated, and interpreted in a way that is reusable, consistent, and independent of any single pipeline.
By separating logic from execution, Ember allows organizations to scale their data platforms without duplicating code or re-implementing the same transformations across pipelines.
Logic defined once
Transformations and rules are expressed declaratively, allowing the same logic to be reused across many pipelines without duplication or drift.
Column-level precision
Logic is defined at the level of individual data attributes rather than entire tables, enabling fine-grained control while keeping pipelines simple and predictable.
Organizational knowledge, captured
Ember encodes shared understanding about data meaning and behavior, turning business logic into a durable asset instead of tribal knowledge embedded in code.
Guardrails for automation
Because logic is explicit and structured, Ember provides a reliable foundation for automation and AI-assisted workflows without introducing unpredictable behavior.
Customization, Where It Belongs
DataForge is designed to handle the vast majority of data integration and transformation needs using its enforced architecture and declarative logic. In practice, this covers most real-world scenarios without requiring custom design and with minimal code.
For the cases that fall outside those patterns, DataForge provides carefully defined extension points where custom logic can be introduced without breaking the surrounding architecture.
Customization is explicit, not implicit
Custom logic is only introduced in designated parts of the pipeline, preventing hidden behavior and one-off patterns from spreading across the platform.
The architecture remains intact
Even when custom processes are required, they operate within Alloy’s enforced layer model and execution structure.
Declarative first, code when necessary
Automated and declarative tools are the default path. Custom code is available for exceptional cases, not as a starting point.
Built for Automation, Not Guesswork
Alloy’s enforced architecture and Ember’s declarative logic create a data platform with explicit structure and governed behavior. Pipelines follow known structures. Logic is explicit, reusable, and governed. There are no hidden stages or implicit behaviors.
This foundation is what makes AI-assisted automation practical.
Because the platform behaves consistently, a conversational AI interface can reason about change, understand intent, and safely propose or apply updates without introducing hallucinations or fragile workflows.
Talos is DataForge’s AI-powered conversational interface that translates natural language into action, operating within the guardrails defined by Alloy and Ember rather than bypassing them.
AI works when the system underneath it is designed to be understood.